考虑一个典型的指令执行周期:取指令->指令译码->取操作数->执行->存结果。 在整个过程中,内存单元只看到地址流,但并不知道这些地址是如何产生的或它们是什么地址。 相应地,可以忽略内存地址是如何由程序产生的,而只是对由运行中的程序产生的内存地址感兴趣。
目录
程序的分段和内存的使用
内存的使用:将程序放到内存中,PC指向开始地址。
重定位:修改程序中的地址(相对地址,也成为逻辑地址),映射到真实内存的物理地址的过程。
什么时候完成重定位:
-
编译时
编译时重定位的程序只能放在内存固定位置,不灵活,但是它效率高,因为载入的时候什么都不用做了。不用每个逻辑地址加一个基地址(比如1000)去得到下一个内存实际地址。 -
载入时
载入时重定位的程序一旦载入内存就不能动了。载入时需要重定位,会浪费时间,但是灵活一些,我们可以找一段空闲的内存,然后把它载入进来,重定位程序里面的地址。但是一旦程序载入到了内存中,那么在程序运行的过程中它就不能动了。如果你想把程序挪到另外的地方,那就不行了。
重定位其实有3种:编译时,加载时,执行时。绝大多数计算机都采用执行时重定位
交换
很多时候程序载入后还需要移动,那怎么办?
——引入交换的概念。
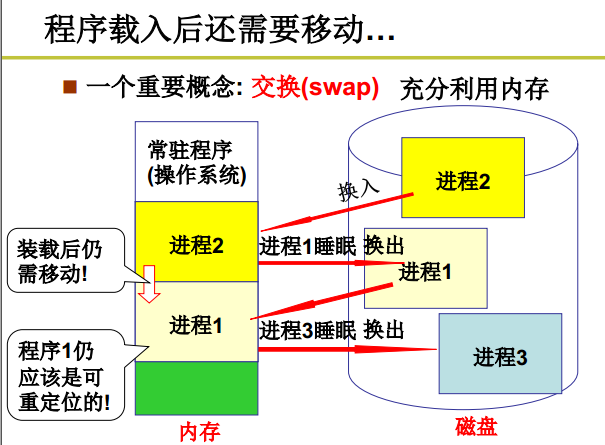
因为内存总是有限的,启动的程序都是放在磁盘上的,内存相比磁盘来说很小,而磁盘却很大,进程在执行的过程中很可能阻塞,那就会把它放到磁盘上,把磁盘上的其它进程换进来。它这样来回换,再次回来内存时的地方与它之前的可能就不一样了。这就需要执行时重定位。
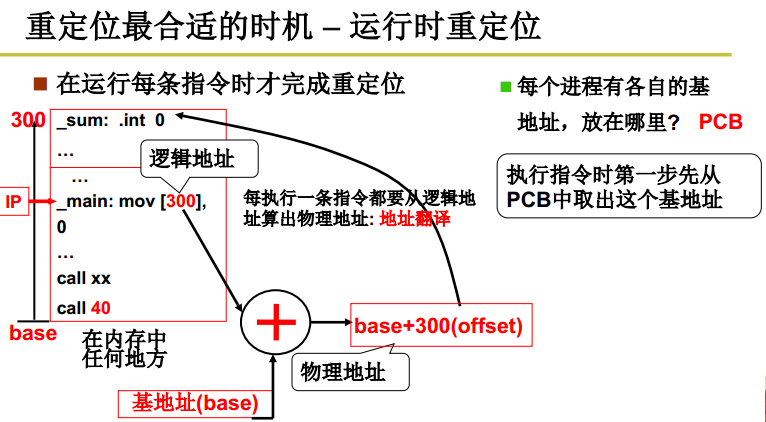 一个可执行程序要运行,首先在内存中找到一段空闲单元,把空闲内存的基地址拿出来,放到进程PCB里面,然后把这段可执行程序放到这段空闲内存中。
一个可执行程序要运行,首先在内存中找到一段空闲单元,把空闲内存的基地址拿出来,放到进程PCB里面,然后把这段可执行程序放到这段空闲内存中。
在上下文切换时(进程),旧进程的PCB的基址保存基址寄存器里面的内容,新进程的PCB里面的基址放到基址寄存器里面。
每执行一条可执行程序里面的程序跳转指令都要进行翻译:把基址寄存器里面的地址拿出来加上这条指令在可执行程序里面的逻辑地址,就是在内存中的地址。
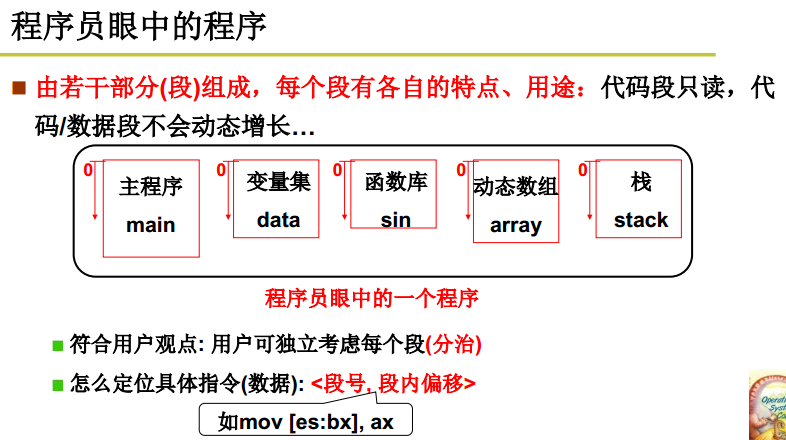
分段
程序是分段的,代码段,数据段…每一部分都从0开始。
程序分段后再将每个段载入内存,这个时候怎么运行呢?操作系统通过GDT表(全局描述符表,Global Descriptor Table)和LDT表(局部描述符表,Local Descriptor Table)来运行程序。
内存的分区与分页
有一个面包,有一堆孩子要吃,怎么办?
- 等分,操作系统初始化时将内存等分成k个分区
- 但孩子有大有小,段也有大有小,需求不一定 ——固定分区与可变分区
可变分区的管理
-
首次适应
分配找到的第一个足够大的面包块。找的方法可以从头开始找,也可以从上次找到的地方开始找。 -
最佳适应
分配最小的足够大的面包。必须查找整个表,除非列表按大小排序。 -
最差适应
分配最大的面包。也要查找整个表,除非列表按大小排序。
内存分页
引入分页:解决内存分区导致的内存效率问题
现在只剩下2块面包,一块150大小,另一块50大小,来了个孩子要至少160大小的面包怎么办?
这就是内存碎片问题。解决办法就是把两块面包合在一起分给孩子,也就是内存紧缩。
内存紧缩需要移动段(复制内容)。但复制是非常花时间的操作,所以不可行。
因此我们需要对内存分页。
内存分页:
将面包切成一片一片的,分给孩子的时候也是一片一片地分,直到满足他的要求为止。
多级页表和快表
为了提高内存的空间利用率,页应该小,但是页小了页表就大了,页表很大之后,页表放置就成了问题。
解释:
页号:页号指的是逻辑地址的页。
页架号:指的是物理内存的页架
多级页表
假设计算机是32位的,内存大小最多是2^32=4G。如果页面尺寸为4K,那么就有4G/4K=1M=2^20个页面。
如果这1M个页表都要放在内存中,那么就需要4MB内存,如果系统并发10个线程,就需要40M内存。
实际上大部分逻辑地址是程序用不到的(假如一个hello word程序只用到了0~10这几个逻辑地址,那么它就不需要存除0-10以外的页号和页架号的对应关系)。
如果在页表中不保存这个进程不会用到的内存,那么查找这个页表会很慢。
-
页表的查找:顺序查找代价太大,可以通过二分查找进行。
-
多级页表:既让内存连续,又让占用的内存少,类似于书的章目录和节目录
页目录表(章)+页表(节):
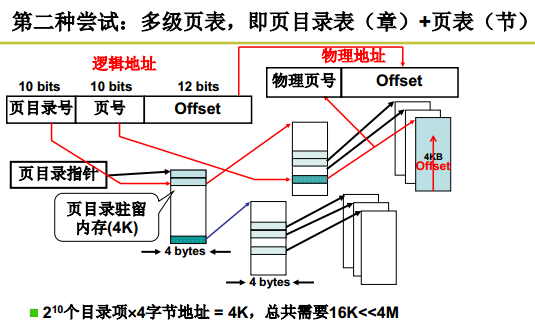
对于16k的解释:
上图中,只有上面两个浅蓝色的地方和最下面一个深绿色的地方放了页表的地址,其他地方没有页表的地址。因此要和这个页目录表连在一起的页表一共3个,再加上一个页目录表,所以是16k。注意,最上面那个页表它没有画。
快表
先去快表中去查,如果快表中没有,再去找多级页表。这样做的主要目的就是为了节省时间。
快表:TLB(Translation Lookaside Buffer)是一组相联快速存储,是寄存器
为什么TLB的条目数只有64-1024就能起作用:
因为程序多为循环和顺序结构
虚拟内存
段、页同时存在的时候,因为段面向用户,页面向硬件。因此需要将两者挤在一起,对应起来,就用到了虚拟内存的概念。
段、页同时存在时它的重定位过程:
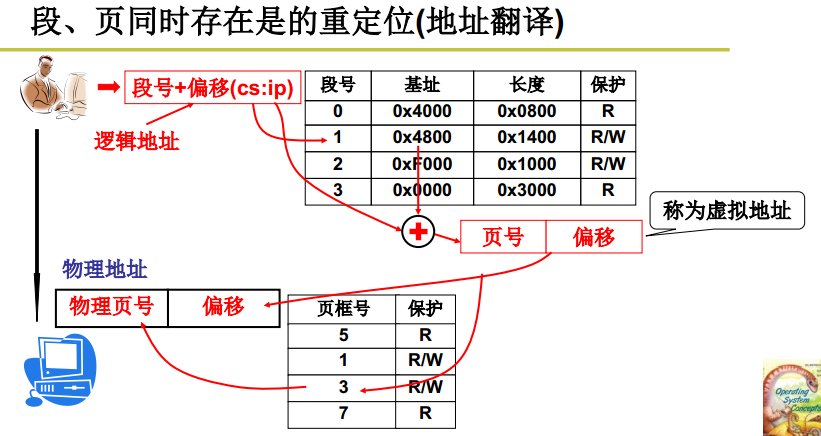
用户的逻辑地址还是段号加上段的偏移(cs+ip),首先根据段表找到基址,这个基址为0x4800,再加上段的偏移就产生了虚拟地址,这个虚拟地址需要再经过一层映射,这层映射是支持分页机制的,所以要根据他的虚拟地址算出它的页号,得到他的页号之后得到页架号,再根据页内偏移得到它的物理地址。最后,操作系统把这个物理地址发在地址总线上,实现想要的操作。
所以上面是两层,第一层地址翻译是基于段的,所以是支持分段的,第二层基于页的地址翻译,是支持分页的。
内存的换入
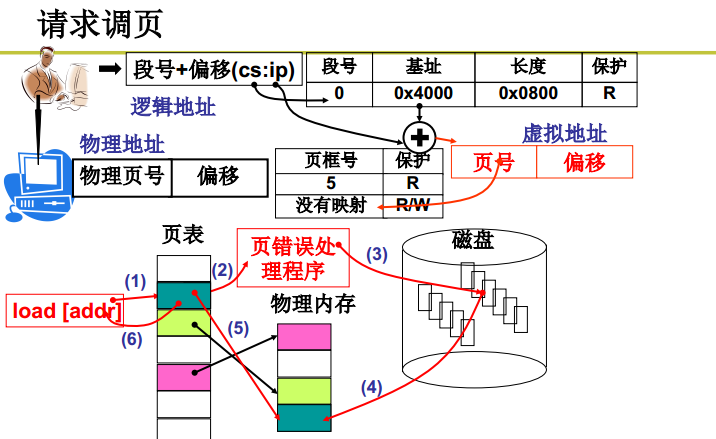
一个程序逻辑地址0-4G我随便访问,根据虚拟地址中划出来的基址一算,算出一个虚拟地址来,这个虚拟地址是随意的。这给用户的感觉就是0-4G我可以随便使用。但是当这个0-4G要真的去映射物理页的时候,去查页表,发现这个页没有,这页没在内存中。这个时候操作系统就需要去调页了,这个页在磁盘中。
没人访问这个地址我把它调进来就没有意义,请求才调。那么访问这个地址了,MMU一查页表,发现缺页,一缺页,我这个程序就不能向下执行了,硬件发出缺页中断。然后进行页错误处理程序。
中断处理程序从仓库中去调入这一页,然后从内存中找一个空闲页面,然后把这一页从磁盘上装进去。这时候中断处理完事了。
这个时候再继续回来向下执行。从用户的角度来看好像什么事情都没有发生过,因为中断这里对用户来说是完全透明的。
采用请求调页而不是请求调段的原因?
请求调页对用户更透明
内存换出
这部分参考:这里
有换入,就应该有换出!
并不能总是获得新的页,因为内存是有限的
页面置换算法
在程序运行过程中,如果要访问的页面不在内存中,就发生缺页中断从而将该页调入内存中。此时如果内存已无空闲空间,系统必须从内存中调出一个页面到磁盘对换区中来腾出空间。
页面置换算法和缓存淘汰策略类似,可以将内存看成磁盘的缓存。在缓存系统中,缓存的大小有限,当有新的缓存到达时,需要淘汰一部分已经存在的缓存,这样才有空间存放新的缓存数据。
页面置换算法的主要目标是使页面置换频率最低(也可以说缺页率最低)。
- 最佳
OPT, Optimal replacement algorithm
所选择的被换出的页面将是最长时间内不再被访问,通常可以保证获得最低的缺页率。 是一种理论上的算法,因为无法知道一个页面多长时间不再被访问。
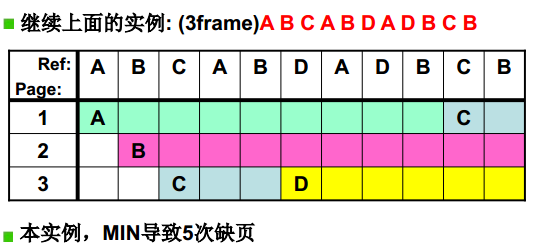
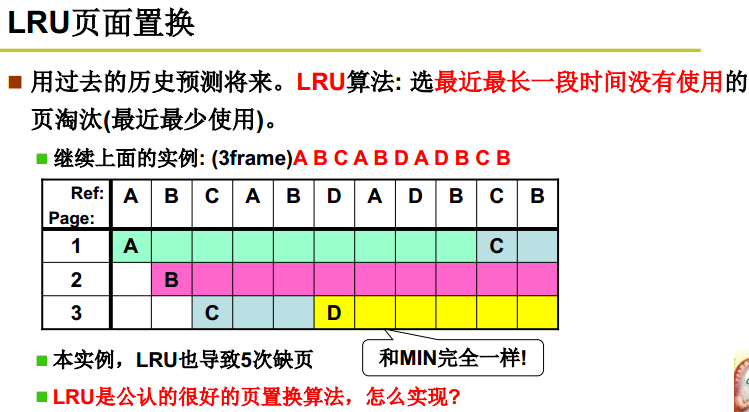
- 最近最久未使用
LRU, Least Recently Used
虽然无法知道将来要使用的页面情况,但是可以知道过去使用页面的情况。LRU 将最近最久未使用的页面换出。
- 先进先出
FIFO, First In First Out
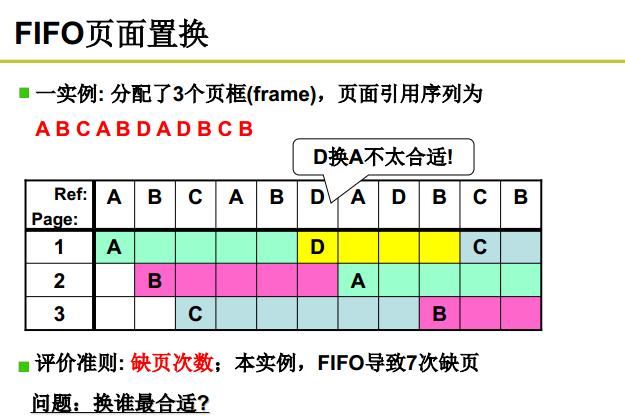
选择换出的页面是最先进入的页面。
该算法会将那些经常被访问的页面也被换出,从而使缺页率升高。
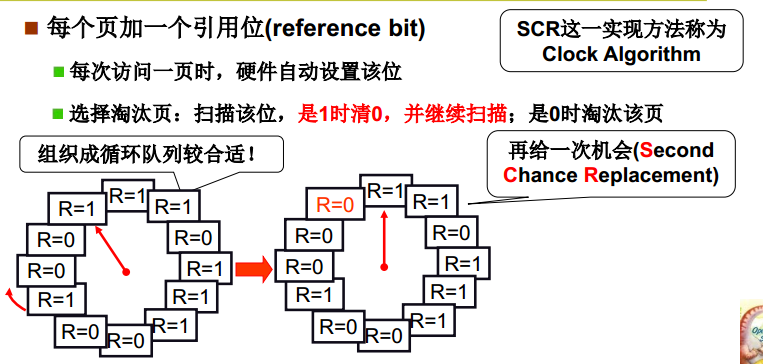
- 时钟
Clock 时钟算法使用环形链表将页面连接起来,再使用一个指针指向最老的页面。
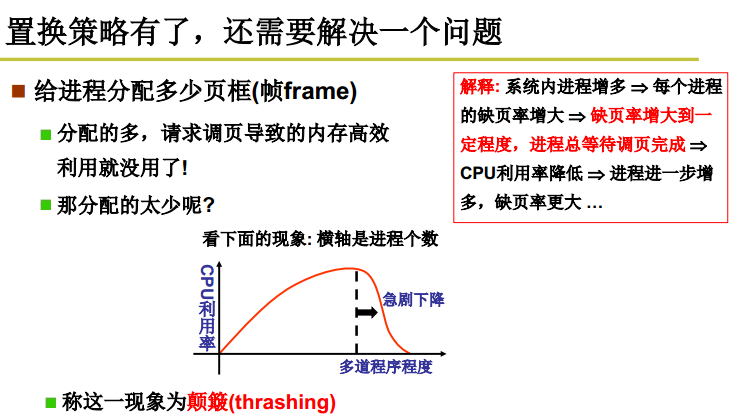
颠簸
进程数目增加到一定程度,CPU利用率急剧下降。